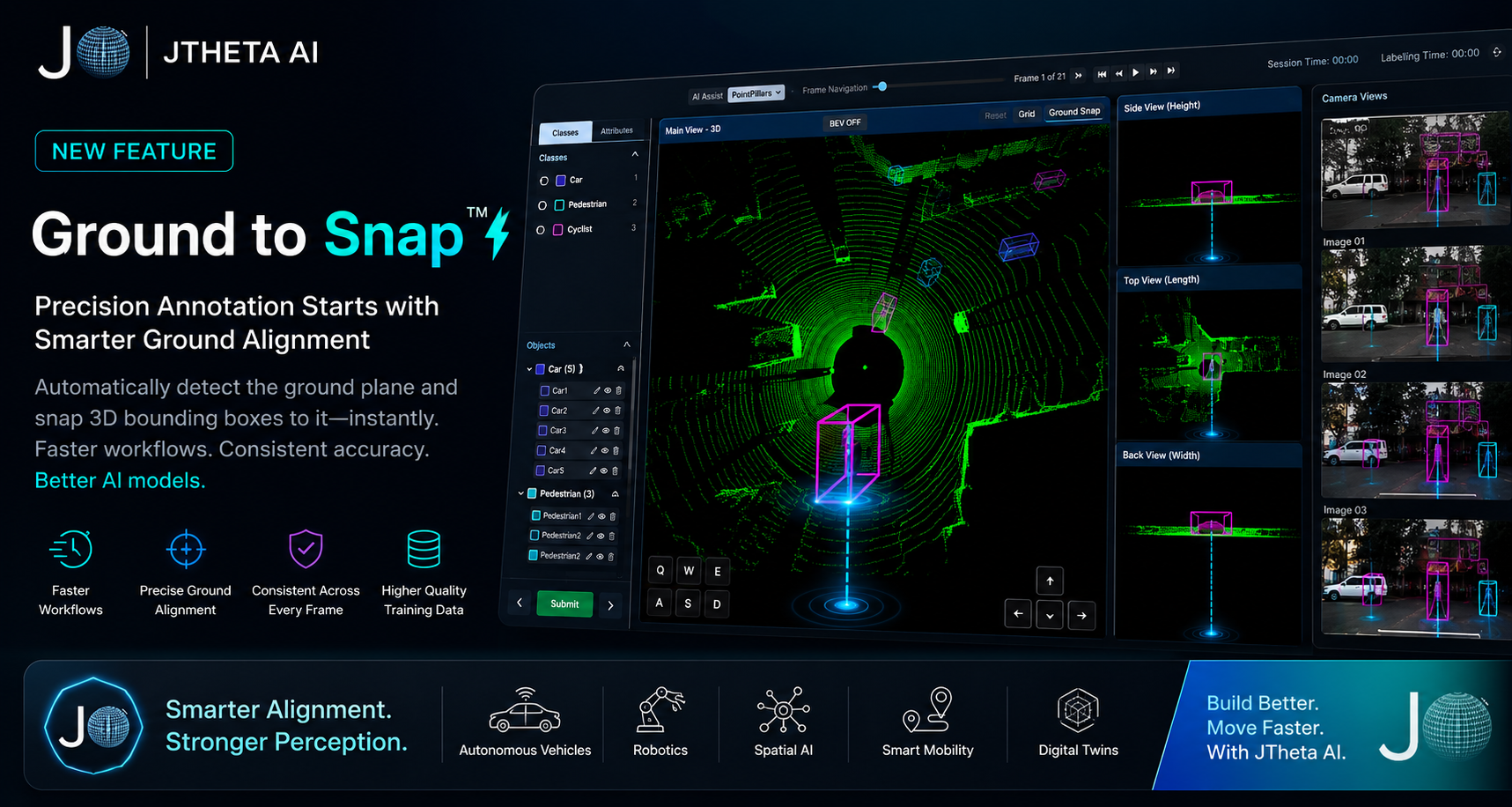
Ground to Snap ⚡
Precision annotation starts with smarter ground alignment
The Problem: Why Ground Alignment Matters
In LiDAR and 3D perception workflows, even millimeter-level inconsistencies at ground level cascade into annotation errors, misaligned bounding boxes, and degraded model performance. Manual frame-by-frame corrections slow annotation pipelines significantly — especially at the scale required by modern AI development.
The result: inconsistent training data, longer review cycles, and models that struggle to generalize in the real world.
What Is Ground to Snap?
Ground to Snap, built by JTheta AI, intelligently detects the ground plane within a LiDAR point cloud and automatically aligns 3D bounding boxes and annotated objects to it — in a single action.
Instead of tedious manual adjustments, annotators can snap objects to the correct ground level instantly, maintaining spatial consistency across every frame of a dataset.
Critical for Perception Pipelines
Accurate ground alignment is foundational to training reliable models across a wide range of perception tasks:
- Vehicle detection
- Pedestrian tracking
- Cyclist recognition
- BEV (Bird’s Eye View) modeling
- Sensor fusion accuracy
- High-quality training dataset generation
What Teams Gain
- Faster annotation workflows — eliminate manual ground adjustment across thousands of frames
- Improved bounding box alignment — objects sit precisely on the detected ground surface, not floating or clipping
- Reduced QA correction cycles — consistent alignment from the start means fewer review rounds
- Cross-frame consistency — maintain spatial grounding uniformly across an entire dataset
- Higher-quality training data — cleaner annotations translate directly to better-performing perception models
Works Across All Annotation Views
Ground to Snap operates within JTheta AI’s multi-view LiDAR environment, allowing teams to validate ground alignment from every angle simultaneously:
- Main 3D view
- Side view
- Top-down view
- Back view
- Multi-camera synchronization
Built for the Spatial Intelligence Stack
Ground to Snap is part of JTheta AI’s broader toolkit for teams building perception systems across autonomous vehicles, robotics, smart mobility, computer vision, spatial AI, and digital twin systems.
Ready to Accelerate Your LiDAR Annotation?
Explore how Ground to Snap and JTheta AI’s full platform can improve your 3D labeling pipeline.
