
Your AMR Didn’t Fail — Your Ground Truth Did
Autonomous mobile robots operating outdoors rarely fail because the model is “bad.”
They fail because the ground truth they were trained and validated against was never truly correct.
In warehouses, ambiguity is the exception.
On construction sites and farms, ambiguity is the operating condition.
Yet many AMR perception pipelines still assume ground truth is objective, stable, and universally interpretable.
It isn’t.
Ground Truth Is Not Absolute in Construction and Agriculture
Ground truth works well when environments are:
Structured
Static
Predictable
Outdoor AMRs operate in environments that change hourly, sometimes minute-by-minute.
Construction Example
A site robot encounters a stack of rebar partially covered with a tarp:
Is it an obstacle? Yes.
Is it static? Probably.
Is it part of the planned work area? Also yes.
Different annotation teams may label:
The rebar as a solid obstacle
The tarp as clutter
The combined structure as free space above a certain height
Each label is “reasonable.” Together, they produce inconsistent supervision.
Agriculture Example
An autonomous tractor navigates through a field with:
Crop residue from previous harvest
Uneven soil compaction
Tall weeds along row edges
Is the residue an obstacle?
Is the weed line drivable at reduced speed?
Does “ground” even mean the same thing across crop stages?
Binary labels flatten decisions that are operationally conditional.
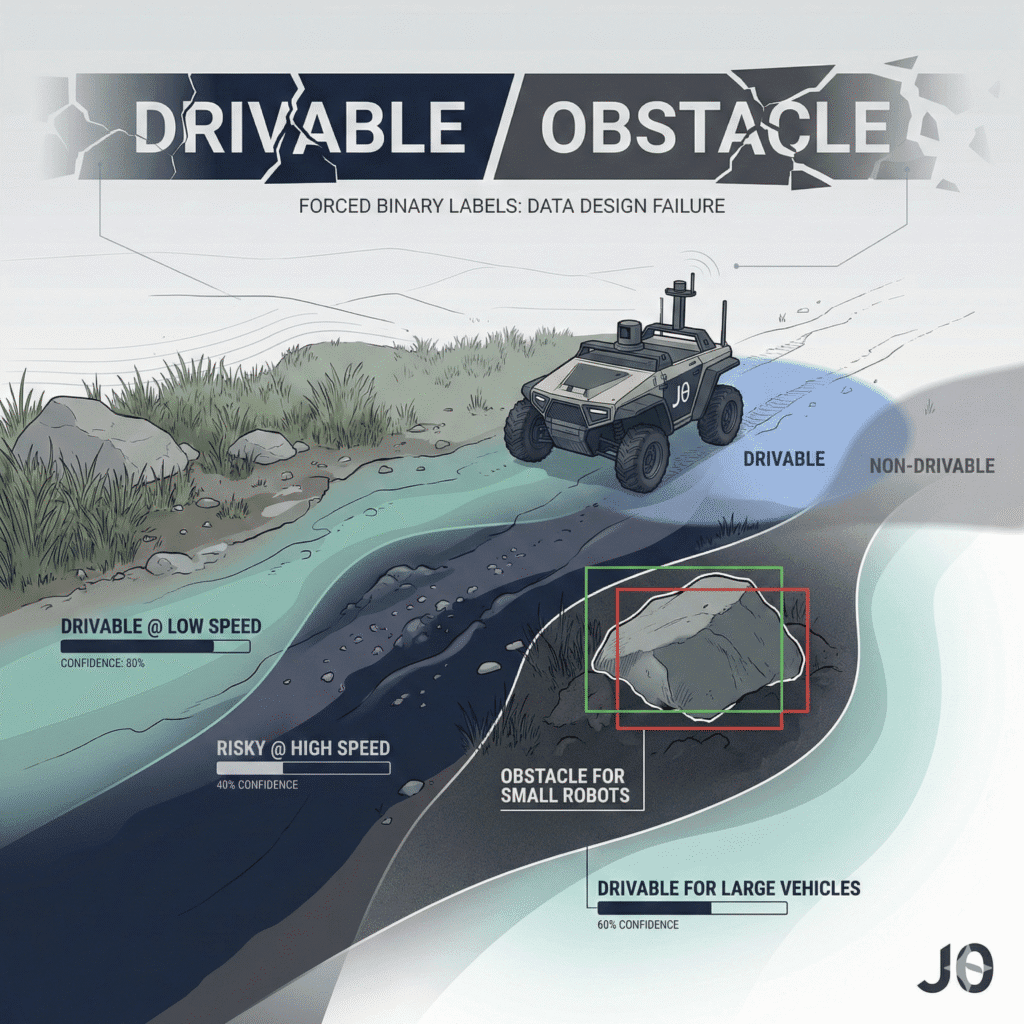
Ambiguous Labels Are Not Annotation Errors — They’re Data Design Failures
In outdoor autonomy, many labels are inherently contextual:
Drivable at speed X, not universally drivable
Obstacles relative to vehicle geometry
Vegetation with density thresholds
Terrain dependent on moisture and slope
When annotation guidelines force annotators to choose a single “correct” answer, ambiguity doesn’t disappear.
It just becomes invisible.
Models trained on this data behave inconsistently because they were taught certainty where none exists.
Inconsistent Ground Truth Across Sites Is a Scaling Killer
Most Wave-1 AMR companies operate across:
Multiple construction sites
Different farms, soil types, and crop cycles
Varying operator expectations
Small interpretation differences accumulate:
Construction
Loose gravel labeled as drivable on one site, obstacle on another
Temporary fencing treated as static in one dataset, dynamic in another
Agriculture
Crop rows annotated tightly in early growth stages, loosely later
Furrows treated as terrain vs obstacles depending on annotator judgment
The result is a model that:
Performs well during demos
Degrades when moved to a new site
Appears “fragile” despite strong offline metrics
This is often blamed on domain shift.
More often, it’s ground truth drift.
The Hidden Cost of “Good Enough” Ground Truth
When ambiguous or inconsistent labels enter the pipeline, teams see:
Unstable perception confidence
Planner oscillations between overly cautious and unsafe
Validation failures that can’t be reproduced offline
Metrics that lose credibility with field teams
At that stage, collecting more data doesn’t help.
It amplifies the noise.
What Production-Grade Ground Truth Looks Like for Outdoor AMRs
High-performing AMR teams treat ground truth as a system, not a task.
That means:
1. Context-Aware Label Definitions
Labels tied to:
Vehicle type
Operational mode
Environment state
“Drivable” without context is not a useful label outdoors.
2. Explicit Representation of Uncertainty
Soft boundaries, confidence ranges, and conditional classes reflect reality better than forced binaries.
3. Cross-Dataset Consistency Controls
Quality is measured across sites and time, not just per-frame accuracy.
4. Temporal Coherence
Outdoor ambiguity resolves over sequences, not frames.
Time-consistent annotation is essential for reliable perception.
Why This Is Where Many AMR Pipelines Break
Modern perception architectures are rarely the limiting factor.
What constrains autonomy in construction and agriculture is how reality is translated into training data.
If ground truth encodes oversimplified assumptions, the model will confidently make the wrong decision.
That’s not a perception failure.
It’s a data definition failure.
A Quiet Pattern We See Across AMR Programs
Teams that make progress beyond pilots tend to do one thing differently:
They stop asking,
“Why did the model fail?”
And start asking,
“Was our ground truth ever valid for this situation?”
This shift usually precedes:
Better field reliability
More explainable failures
Faster iteration cycles
At JTheta, we’ve seen that autonomy teams don’t need more labeled data — they need ground truth that respects environmental complexity and remains consistent as deployments scale.
Final Thought
Outdoor autonomy isn’t about eliminating ambiguity.
It’s about encoding it honestly in data.
Until ground truth reflects how construction sites and farms actually behave, AMRs will keep “failing” in ways that were predetermined long before deployment.

