Training Data Quality: Lessons from 10,000+ Real-World AI Projects
AI teams often ask, “Which model architecture should we use?”
From our experience across 10,000+ production AI projects, the better question is:
“Can we trust our training data?”
Across industries and modalities, we’ve seen advanced models fail — not due to weak algorithms, but because the data feeding them was noisy, inconsistent, or misaligned with real-world conditions. At JTheta.ai, training data quality is not a checklist item; it is an engineering discipline.
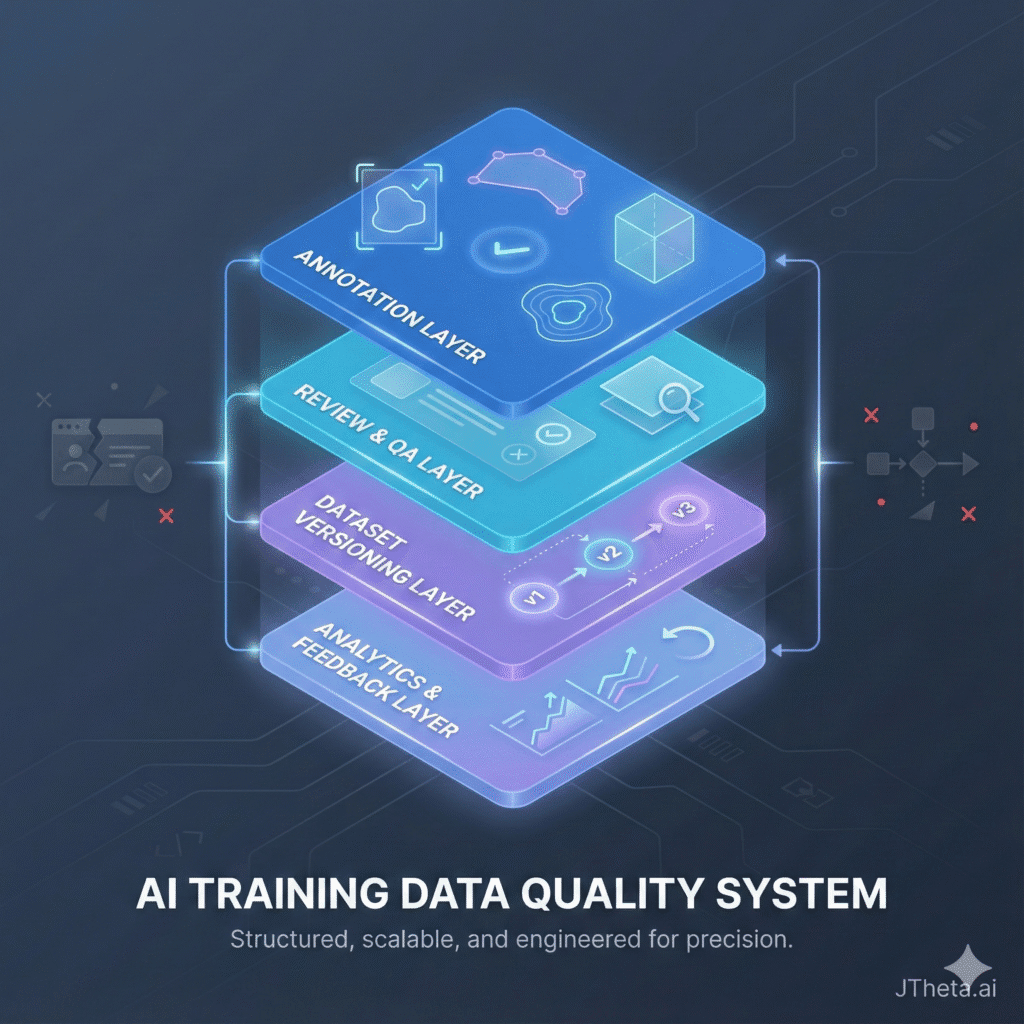
1. Training Data Quality Is a Systems Problem (Not a Labeling Problem)
One of the biggest misconceptions in AI development is treating data quality as a post-collection cleanup task. In practice, quality issues compound across the entire ML lifecycle:
- Ambiguous label definitions propagate inconsistencies
- Poor annotation tools introduce human error
- Missing edge cases reduce model robustness
- Lack of version control makes regressions invisible
From thousands of workflows on JTheta.ai, we’ve learned that data quality must be designed into the system, not enforced after the fact.
👉 Related read: https://www.jtheta.ai/computer-vision-ml-research
2. Cross-Industry Signals: Same Problems, Different Consequences
Although industries differ, data quality failure patterns remain strikingly consistent.
Healthcare & Medical Imaging
- Minor annotation inaccuracies can alter clinical model sensitivity
- Inter-annotator disagreement is one of the biggest hidden risks
- Structured QA and expert-driven reviews consistently outperform speed-first approaches
Autonomous Systems & Robotics
- Long-tail scenarios (rare objects, unusual lighting) dominate model failure
- Class imbalance silently degrades perception reliability
- Frame-to-frame consistency matters more than single-frame accuracy
Enterprise & Industrial Vision
- Inconsistent labeling taxonomies inflate retraining cycles
- Dataset drift is often detected only after deployment issues surface
Across domains, training data quality directly correlates with deployment stability, not just offline accuracy.
3. Quality Dimensions That Actually Move Model Metrics
From empirical project analysis, five quality dimensions consistently influence downstream performance:
- Annotation Accuracy – Ground truth correctness at pixel, object, or instance level
- Schema Consistency – Stable class definitions and attribute usage
- Coverage & Diversity – Balanced representation of real-world conditions
- Temporal & Contextual Coherence – Especially critical for video and LiDAR
- Version Traceability – Ability to track dataset evolution over time
Teams that actively manage these dimensions see:
- Faster convergence during training
- Lower error variance in validation
- Reduced post-deployment fixes
Explore how structured annotation workflows enable this:
👉 https://www.jtheta.ai/documentation
4. Modality-Specific Insights from Production Workflows
2D Image Annotation
- Polygon and segmentation accuracy matters more than bounding box count
- Over-labeling introduces noise just as much as under-labeling
- Clear visual guidelines outperform textual instructions alone
Medical Imaging (DICOM, NIFTI)
- Annotation precision must align with clinical relevance, not visual clarity
- Multi-reviewer validation dramatically improves reliability
- Dataset versioning is essential for auditability
LiDAR & 3D Point Clouds
- Spatial consistency across frames is a leading quality indicator
- Class hierarchy errors cascade into downstream perception stacks
- Poor cuboid alignment creates compounding depth errors
High-quality data looks different across modalities, but systematic quality controls apply universally.
5. Why Manual QA Alone Does Not Scale
Many teams rely on spot checks or manual reviews to enforce quality. At small scale, this works. At production scale, it fails.
What we’ve learned:
- Manual QA catches visible errors, not systemic ones
- Inconsistent reviewers introduce new variability
- Lack of feedback loops prevents continuous improvement
Scalable quality requires:
- Defined annotation standards
- Structured review workflows
- Dataset-level analytics
- Versioned exports for controlled iteration
This is where annotation platforms become infrastructure — not tools.
6. From Quality Control to Quality Engineering
The most successful teams treat training data quality as an engineering problem, not an operational task.
They:
- Design datasets with model objectives in mind
- Track quality metrics alongside model metrics
- Iterate on annotation schemas, not just labels
- Use versioned datasets as first-class ML artifacts
At JTheta.ai, we see a clear pattern:
Teams that invest early in data quality move faster later — with fewer surprises.
After 10,000+ projects, one conclusion is unavoidable:
Model performance is capped by training data quality.
As AI systems move from experimentation to real-world deployment, data quality becomes the strongest predictor of trust, safety, and scalability.
If your AI roadmap depends on consistent, high-quality training data, explore how JTheta.ai enables production-ready annotation workflows:
👉 https://www.jtheta.ai/