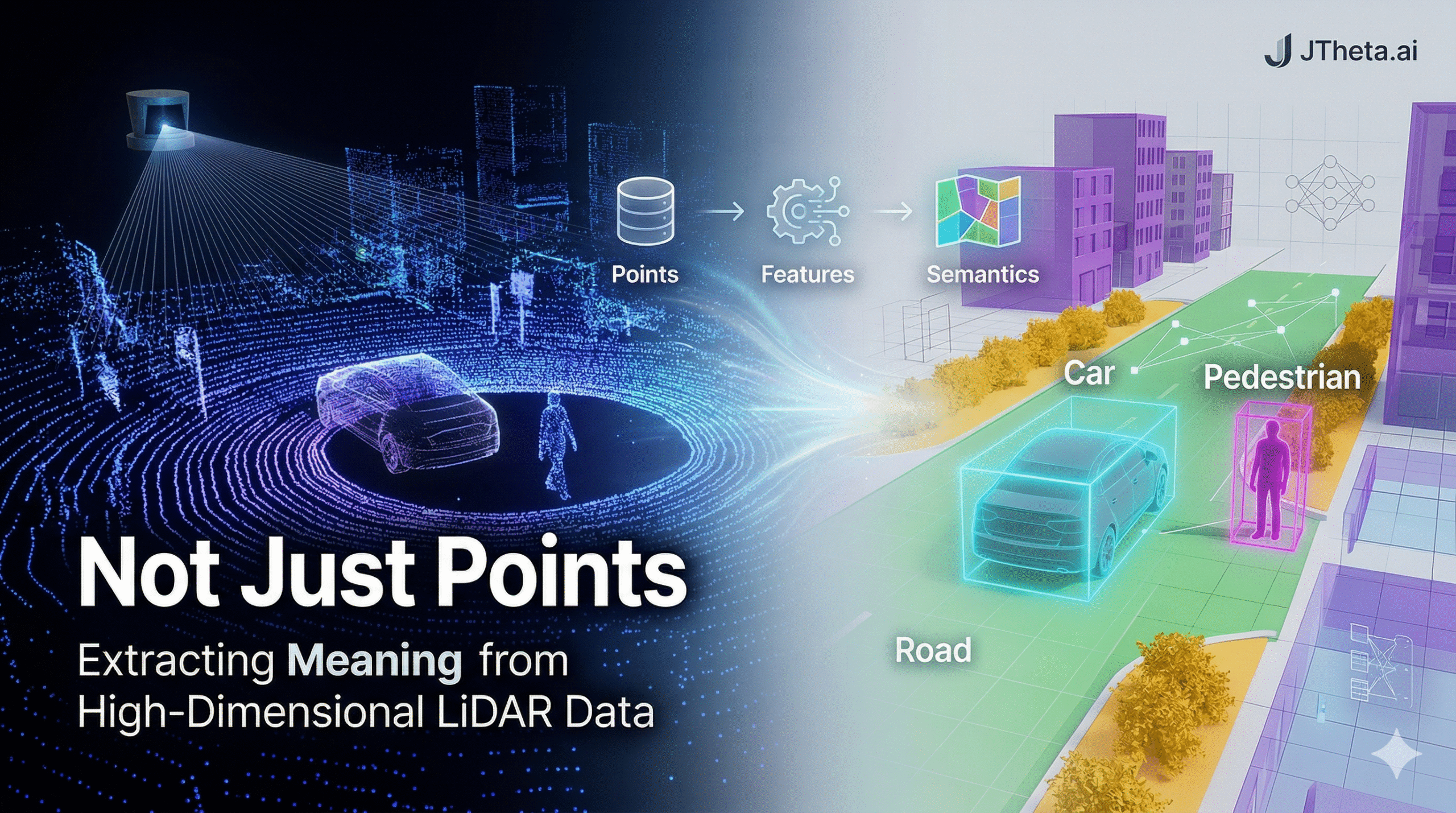
Not Just Points: Extracting Meaning from High-Dimensional LiDAR Data
A LiDAR scan doesn’t give you a scene — it gives you billions of raw measurements. The real challenge is turning that chaos into understanding.
The curse of raw geometry
Light Detection and Ranging (LiDAR) sensors fire millions of laser pulses per second, recording the precise 3D coordinates of every surface they strike. The result is a point cloud — a dense constellation of (x, y, z) coordinates that faithfully captures the geometry of the physical world.
But geometry alone is mute. A point cloud of an urban street doesn’t tell you which points are a pedestrian about to step off the curb, which form the chassis of a parked truck, and which describe the static geometry of a building facade. Raw coordinates have no labels, no context, no semantics.
This is the fundamental challenge at the heart of modern 3D perception: bridging the gap between a cloud of floating numbers and a machine-readable understanding of a scene.
What makes LiDAR data high-dimensional?
Each point is, at minimum, a coordinate triple. But modern LiDAR sensors append a rich set of additional channels — intensity of return, number of returns per pulse, return index, azimuth angle, timestamp, and in some systems, near-infrared reflectance. Aggregated across millions of points, this becomes a high-dimensional data structure that dwarfs what classical geometry pipelines were designed to handle.
The dimensionality compounds further at the representation stage. Downstream algorithms may encode each point’s local neighborhood using hand-crafted geometric descriptors (normals, curvatures, eigenvalue ratios), learned embeddings from deep networks, or both. A single point can carry a feature vector of hundreds of dimensions before any task-specific processing begins.
The processing pipeline: from pulses to perception

Three approaches to semantic extraction
The field has converged on three broad strategies for extracting meaning from point clouds, each with distinct trade-offs between accuracy, compute, and robustness.
Voxel-based methods discretize the continuous point cloud into a regular 3D grid of volumetric cells (voxels). Each cell aggregates the points it contains into a fixed-size feature vector. The regular structure enables the use of 3D convolutional networks — powerful but memory-hungry, as voxel grids grow cubically with resolution.
Point-based methods operate directly on the unordered set of 3D points, bypassing discretization entirely. PointNet, the seminal architecture from 2017, demonstrated that a simple multi-layer perceptron applied independently to each point, followed by a global max-pool, can learn surprisingly rich shape representations. Subsequent work (PointNet++, KPConv) introduced local neighborhood aggregation to capture fine-grained geometric structure.
Graph-based and transformer methods treat each point as a node in a dynamic graph, with edges connecting nearby points. Graph convolutional networks propagate features across these edges, while point cloud transformers apply self-attention across local or global point sets. These approaches currently achieve state-of-the-art results on major benchmarks but carry significant computational overhead.
Key tasks: what "meaning" actually means
Semantic extraction from LiDAR typically targets four distinct perception tasks:
- Semantic segmentation — assign a class label (road, building, vegetation, vehicle, pedestrian) to every point. The output is a fully labeled point cloud, useful for mapping and scene understanding.
- Instance segmentation — go beyond class labels to distinguish individual object instances. Separating a crowd of pedestrians into discrete, tracked individuals is a fundamentally harder problem than simply labeling points as “pedestrian.”
- 3D object detection — localize and classify objects within oriented bounding boxes. Autonomous vehicles need not just to know that a car exists, but precisely where it is, how it is oriented, and how fast it is moving.
- Scene flow estimation — estimate the 3D motion vector of every point between consecutive scans. This transforms a static geometric snapshot into a dynamic representation of a moving world.
Where it matters most

The open challenges
Despite remarkable progress, several hard problems remain unsolved at the research frontier.
Sparsity and density variation: A close object may generate thousands of returns; the same object at 100 meters might contribute only a handful of points. Models must generalize across this enormous density range — a challenge classical image CNNs never face.
Domain shift: A model trained on data from a Velodyne HDL-64E sensor performs poorly when deployed on a Hesai Pandar128, even if the physical scene is identical. Sensor-agnostic representations remain an active research direction.
Annotation cost: Labeling 3D point clouds is orders of magnitude more expensive than labeling images. Semi-supervised and self-supervised learning approaches — where models learn from unlabeled scans and require only sparse human annotation — are increasingly central to the field.
Real-time constraints: Edge deployment on autonomous vehicles, drones, or mobile mapping platforms demands inference at 10–20 Hz on hardware with strict power budgets. The most accurate transformer-based models are nowhere near this requirement without aggressive distillation or quantization.
The path forward
The trajectory is clear: LiDAR interpretation is moving from task-specific, hand-engineered pipelines toward large, pre-trained 3D foundation models that can be fine-tuned for diverse downstream tasks with minimal labeled data. Projects like Uni3D, OpenScene, and 3D-LLM explore whether the rich semantic knowledge encoded in vision-language models can be distilled into 3D point cloud encoders — transferring the “common sense” understanding of the world that emerges from 2D internet-scale training into the native 3D domain.
The point cloud was always more than geometry. Every pulse carries the imprint of a material, a surface, a moving thing. The next generation of perception systems won’t just read those imprints — they’ll understand what they mean.
