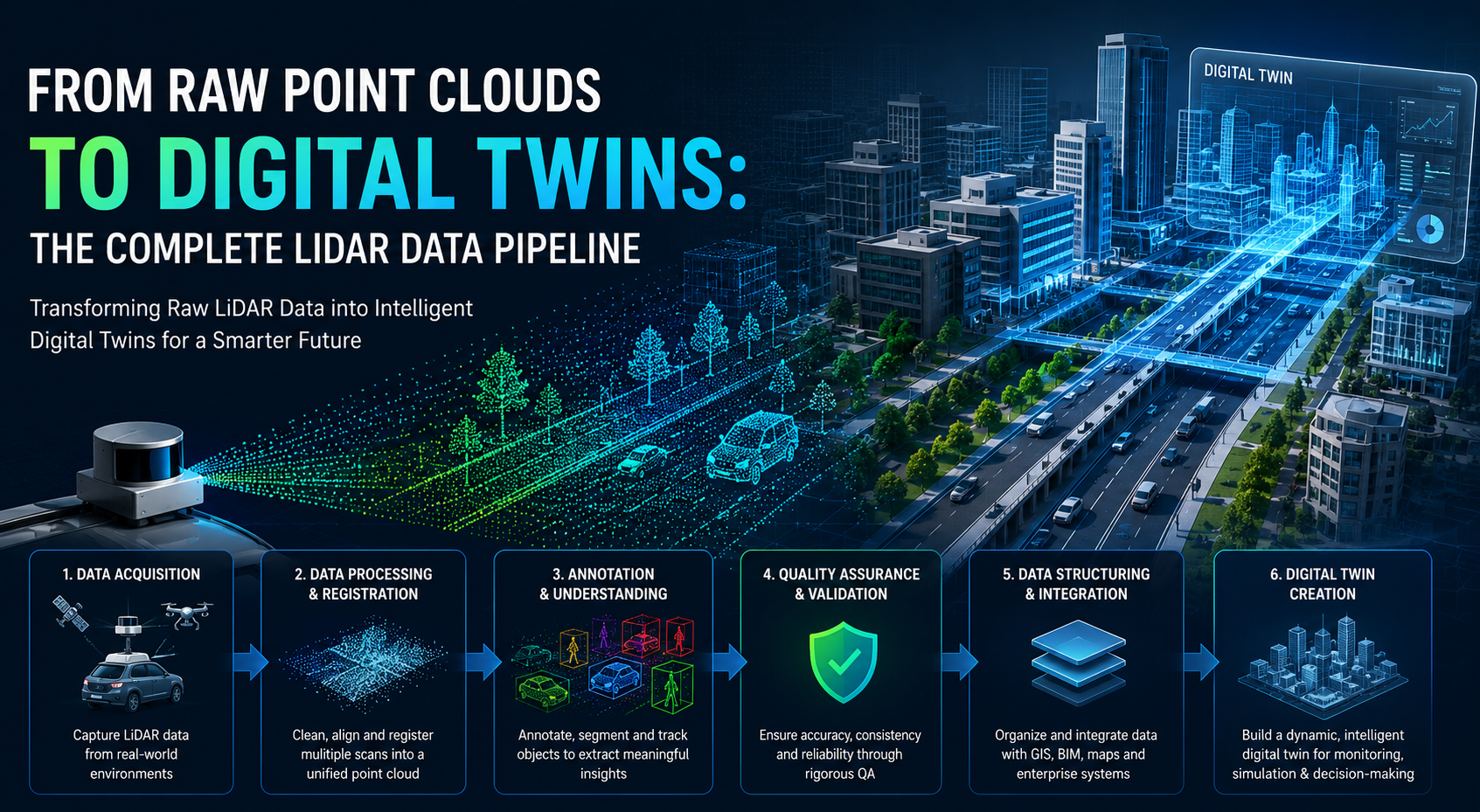
From Raw Point Clouds to Digital Twins: The Complete LiDAR Data Pipeline
Introduction
The world is increasingly being recreated in digital form.
From autonomous vehicles navigating city streets to construction firms monitoring project progress and municipalities building smart cities, organizations are relying on highly accurate digital representations of physical environments. At the center of this transformation is LiDAR (Light Detection and Ranging) technology.
LiDAR sensors capture millions of spatial measurements every second, generating detailed 3D point clouds that accurately represent the real world. However, raw point cloud data alone has limited value. To unlock actionable insights, organizations must transform this data into structured, intelligent digital assets.
This transformation follows a comprehensive LiDAR data pipeline that ultimately enables the creation of Digital Twins—dynamic virtual replicas of real-world environments, infrastructure, and assets.
Let’s explore how raw point clouds evolve into intelligent digital twins.
What Is a Point Cloud?
A point cloud is a collection of millions—or even billions—of individual points captured by LiDAR sensors.
Each point contains:
- X, Y, and Z coordinates
- Distance measurements
- Intensity values
- Timestamp information
- Sensor metadata
When combined, these points create a highly detailed three-dimensional representation of the surrounding environment.
Unlike traditional images, point clouds provide accurate depth and spatial information, making them ideal for autonomous systems, mapping applications, infrastructure management, and digital twin development.
Stage 1: Data Acquisition
Every LiDAR project begins with data collection.
Depending on the use case, LiDAR sensors may be mounted on:
- Autonomous vehicles
- Drones and UAVs
- Mobile mapping systems
- Surveying equipment
- Industrial robots
- Fixed infrastructure systems
During data acquisition, sensors continuously capture environmental information while generating large volumes of raw point cloud data.
The quality of the final digital twin is heavily influenced by:
- Sensor resolution
- Scan frequency
- Environmental conditions
- Vehicle or platform speed
- Calibration accuracy
Accurate data collection forms the foundation of the entire pipeline.
Stage 2: Data Processing and Registration
Raw LiDAR scans are often captured from multiple viewpoints and sensor positions.
To create a unified representation, engineers perform registration—the process of aligning multiple scans into a single coordinate system.
Key processing tasks include:
Point Cloud Registration
Combining multiple scans into one coherent dataset.
Noise Removal
Eliminating unwanted artifacts caused by weather, reflective surfaces, or sensor interference.
Calibration Correction
Adjusting for sensor drift and positional inaccuracies.
Data Alignment
Synchronizing LiDAR data with GPS, IMU, and other sensor inputs.
After processing, the point cloud becomes cleaner, more accurate, and ready for analysis.
Stage 3: Object Detection and Annotation
Raw geometry provides shape information, but machines still need context.
Annotation transforms unstructured point clouds into machine-readable intelligence.
This stage typically involves:
3D Bounding Box Annotation
Objects such as vehicles, pedestrians, cyclists, and equipment are enclosed within precise 3D cuboids.
Semantic Segmentation
Each point is assigned a category label, such as:
- Road
- Building
- Vegetation
- Vehicle
- Sidewalk
- Utility infrastructure
Instance Segmentation
Individual objects are identified separately, even when belonging to the same class.
Object Tracking
Moving objects are tracked across multiple frames, providing temporal context for AI systems.
High-quality annotation is critical because it directly impacts the performance of perception models and digital twin applications.
Stage 4: Quality Assurance and Validation
Even minor annotation errors can significantly affect downstream AI models and analytics systems.
Robust quality assurance processes ensure:
- Annotation consistency
- Accurate object boundaries
- Correct class assignments
- Reliable object tracking
- Dataset completeness
Many organizations adopt Human-in-the-Loop (HITL) workflows that combine AI-assisted labeling with expert human review to maintain accuracy at scale.
Quality validation serves as a crucial checkpoint before data enters production systems.
Stage 5: Data Structuring and Integration
Once annotated and validated, the data must be structured for operational use.
Organizations typically integrate LiDAR datasets with:
- GIS platforms
- BIM systems
- Asset management software
- Simulation environments
- Mapping applications
- Autonomous perception systems
At this stage, data becomes searchable, measurable, and operationally valuable.
The focus shifts from visualization to intelligence extraction.
Stage 6: Building the Digital Twin
With structured spatial data available, organizations can construct a Digital Twin.
A Digital Twin is a living virtual model that mirrors physical assets, infrastructure, or environments.
Unlike static 3D models, Digital Twins continuously evolve using real-world data updates.
A digital twin may include:
- Physical geometry
- Asset information
- Operational status
- Environmental conditions
- Historical performance data
- Predictive analytics
This creates a dynamic representation of reality that supports monitoring, planning, and decision-making.
Applications of Digital Twins
Smart Cities
City planners use digital twins to optimize infrastructure, traffic flow, and urban development initiatives.
Construction and Infrastructure
Project teams monitor construction progress, identify risks, and improve resource allocation.
Autonomous Vehicles
Digital twins help validate perception algorithms, simulate edge cases, and improve autonomous navigation systems.
Industrial Facilities
Manufacturers create virtual replicas of plants and warehouses to improve efficiency and maintenance planning.
Utilities and Energy
Digital twins enable asset monitoring, predictive maintenance, and infrastructure resilience planning.
Challenges in the LiDAR-to-Digital-Twin Workflow
Despite its benefits, the pipeline presents several challenges:
Massive Data Volumes
LiDAR sensors generate terabytes of data that require efficient processing and storage.
Annotation Complexity
Dense environments often require extensive manual review and validation.
Integration Difficulties
Combining LiDAR data with GIS, BIM, and operational systems can be technically complex.
Scalability Requirements
Organizations must balance accuracy, speed, and cost while managing growing datasets.
Overcoming these challenges requires specialized expertise, scalable workflows, and advanced annotation platforms.
How JTheta.ai Accelerates the LiDAR Data Pipeline
At JTheta.ai, we help organizations transform raw LiDAR data into structured, AI-ready datasets that power perception systems and digital twin initiatives.
Our capabilities include:
- LiDAR Annotation
- 3D Bounding Box Labeling
- Semantic Segmentation
- Object Tracking
- Sensor Fusion Annotation
- Human-in-the-Loop Quality Assurance
- Large-Scale Dataset Processing
By combining domain expertise, scalable workflows, and rigorous quality standards, we help enterprises accelerate the journey from raw point clouds to intelligent digital twins.

